Lernendes Sprachassistenzsystem
Kurzbeschreibung
Das hier angebotene Verfahren zur sprachbasierten Unterstützung, erhöht die Erkennungsrate bezüglich des Ansprechverhaltens von Sprachassistenzsystemen. Durch eine Adaptionseinrichtung ist das System in der Lage, Informationen die vorab abgespeicherten und die extrahierten eines individuellen Bedieners, so zu verarbeiten und anzupassen, dass das Sprachmodul auch die neuen Informationen im Anschluss verarbeiten kann.
Beschreibung/Hintergrund
Mithilfe von Sprachassistenzsystem sind die Sprachtranskription, Sprachübersetzung und Sprachsteuerung von Endverbrauchergeräten wie Smartphone, Fernseher, Navigationssystem und Spielkonsolen bedienerfreundlicher und einfacher zu handhaben. Beim jetzigen Stand der Technik existieren hierbei aber zwei Problemfelder. Erstens sind natürliche Sprachen fehlerbehaftet und weisen großen Interpretationsspielraum auf und zweitens muss ein Sprachassistenzsystem von sich aus feststellen, ob eine gesprochenen Sprachakustik an das Sprachassistenzsystem gestellt ist oder nicht. Sprachassistenzsysteme können nicht feststellen, ob ein gesprochenes Kommandowort im Kontext der gesamten Sprachakustik dazu dient, das Sprachassistenzsystem zu bedienen oder ob es z.B. im Kontext Teil einer Konversation zwischen zwei Personen ist.
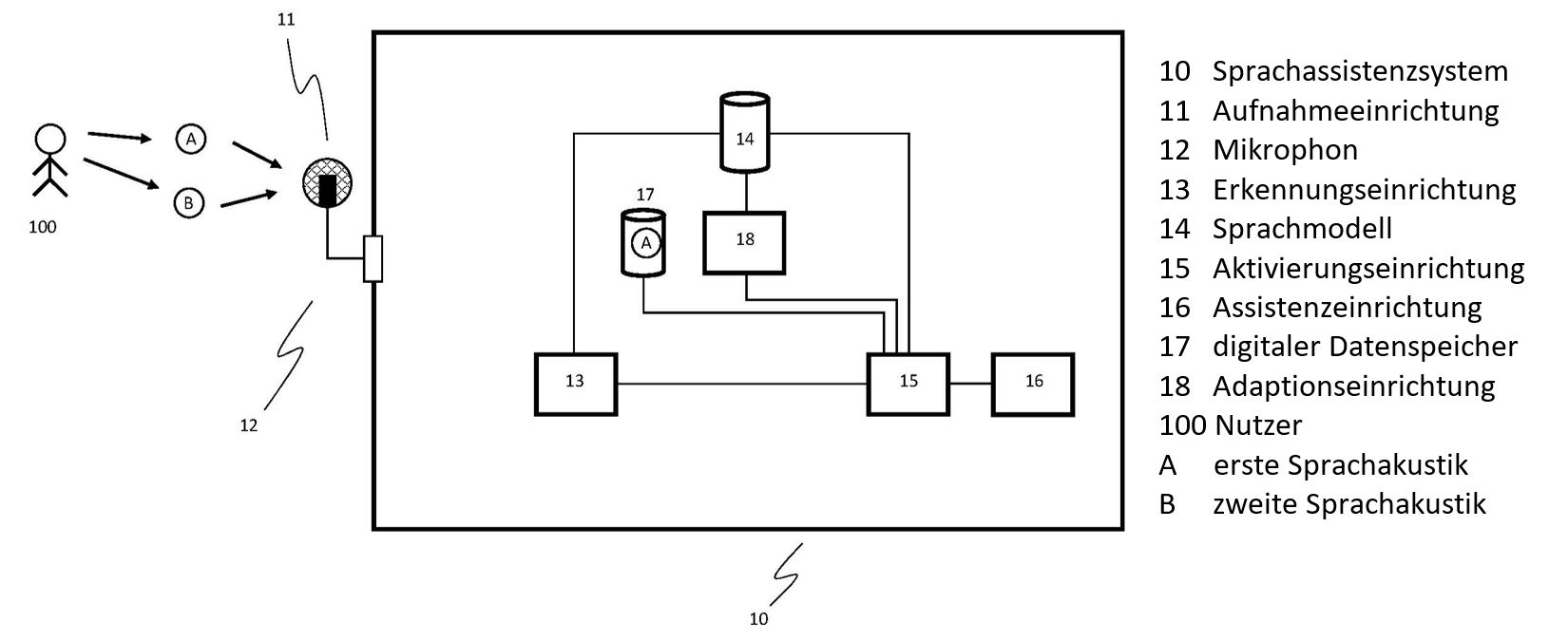
Lösung
Das hier angebotene Verfahren zur sprachbasierten Unterstützung, erhöht die Erkennungsrate bezüglich des Ansprechverhaltens von Sprachassistenzsystemen. Nach der Aufnahme auditiv wahrnehmbare Schallsignale, durch bspw. einen Schallsensor (Mikrofon), werden diese in ein digitales Signal umwandelt. Die Erkennungseinrichtung, versteht mittels einer Recheneinheit die auditiven Schallsignale einer Sprachakustik und extrahiert die sprachbasierten Informationen heraus. Sie ist nicht nur in der Lage sprachliche Inhalte zu erkennen, sondern kann auch prosodische Eigenschaften der Sprachakustik herauszufiltern, wie z.B. Akzente, Tonsprache, Intonation, Tempo, Rhythmus oder Pausen. Diese Informationen werden in der Aktivierungseinheit mittels Sprachmodell erkannt und es wird entschieden, ob durch die sprachinhaltliche und sprachprosodische Information der Akustik eine Aktivierungsabsicht besteht oder nicht. Neu bei diesem Sprachassistenzsystem ist nun, dass ein in einem digitalem Datenspeicher vorab hinterlegtes Modell der Sprachakustik mittels einer an das System gerichtete Sprachakustik extrahierten Information verbessert werden kann, wenn das bisherige Modell für die Erkennung nicht sensitiv genug war (Lerneffekt). Durch diese Adaptionseinrichtung ist das System in der Lage, beide Informationen, die vorab abgespeicherten und die extrahierten eines individuellen Bedieners, so zu verarbeiten und anzupassen, dass das Sprachmodul auch die neuen Informationen im Anschluss verarbeiten kann.